2026-05-30 15:53
wikidodo
![]()
![]()
![]() [permalink]
[permalink]
→ Wikimedia Foundation closes Wikinews after 21 years
Jammer. Er kwam niet super veel op, maar meestel wel gebalanceerd uit neutrale hoek met de nodige nuance... Soit, nóg een (betrouwbare) RSS feed minder...
2026-04-06 23:09
digg2
![]()
![]()
![]()
![]() [permalink]
[permalink]
Dang! I though I'd check why/if the new digg does RSS already, and didn't notice this page was up. Internet 2026 is a harsh place, that's for sure. But in my humble opinion it's more than this bot problem. The real currency is mindspace, and a new attempt at a breeding reactor to cull it from people passing by to find out what's hot and happening, no longer gells with the populace. Any avenue of doing so is covered — friends/family (Facebook), current events (Twitter), business (LinkedIn), etc. — monetization there may have made us all numb enough to instantly sign off from new initiatives. Also any system will be gamed for value, and it's like we're all taken hostage by the system being gamed by a bigger system. No wonder 'interesting newcomers' like ground news and straight arrow news kind of get you to go with a paid subscription from the get-go. Which I fully regret, since (getting help with) being sceptical about the news you read shouldn't cost you anything! It really makes you wonder what MetaFilter did differently and how hard Reddit is working to make it all work. But they're still cooking something. I hope they have a close look at the legal frameworks that are getting drafted (not in the U.S.) and what was actually good about the blue checkmarks before rocket boy showed up with a sink.
WinHttpWS.pas: connect to a websocket using winhttp.dll
2023-03-30 23:02
WinHttpWS
![]()
![]()
![]()
![]() [permalink]
[permalink]
I needed to fetch something from a WebSocket real quick, but the project didn't have anything like networking components included yet. So I decided a quick-and-easy-way to get to what I needed is using winhttp.dll... I share this hoping it may come in handy for anyone else...
2023-03-24 23:42
rss
![]()
![]()
![]() [permalink]
[permalink]
Yes this website has an RSS feed, click here, or one of the others for posts on a specific subject:
















See also: my own RSS reader!
Maybe 'invisibility' will kill RSS
2021-05-19 07:32
invisiblerss
![]()
![]()
![]() [permalink]
[permalink]
How can we make RSS 'more visible'? Among the news-sites I've added the RSS feed to my RSS reader, I see a common thing happen a few times now: They build a new website that looks better, and — bam — the feed URL responds with a 404, or worse a 500, HTTP response. I guess what happens is that by selecting a new platform, the main core feature(s) is provided — listing new articles — in a new design that looks better, and these designers don't know about the feed because they can't see it. Perhaps in most cases it doesn't even show in the page view statistics...
In a better world, they would soon notice a viewership drop especially by the people that would previously follow a link from a feed, but I know full well that us feed-readers are a minority group that's easily left out of the numbers, and that news feeds themselves are a sensitive subject because we're using their content and can't directly generate income.
The least I can do is send an e-mail to a support address if I can find one, notifying I'm getting less service than before. I don't expect them to really do anything about it. Or even respond. I guess we shoud get the message and accept we're not wanted in their slice of the public. Some do restore the feed, or build a feed on the new platform, though. So even I don't get a response, from time to time I check to see if they still love us. (Or if there's a way to get what we want directly from the new platform...)
2021-05-12 22:16
feederopinions
![]()
![]()
![]()
![]() [permalink]
[permalink]
→ https://github.com/stijnsanders/feeder/commit/a34f311394b842ef5dca716be32c31ca979fdb1a
What an idea. Imagine a place where you can vent impressions of the moment, except you have to do so in response to a title and URL that has to have come in over an RSS feed you're subscribed to on beforehand. Could that be something? Or would the ideal public in this specific niche be much to narrow? (It's probably at least one, since it looks like it would at least serve me.)
Ideetje opschrijven, dan vergeten. (En snel.)
2021-03-03 22:07
idee311
![]()
![]()
![]()
![]() [permalink]
[permalink]
Komt er me weer zo'n uitgekookt idee binnenvallen dat ik waarschijnlijk niets mee ga kunnen doen. Opschrijven dan maar zeker? Is het minste dat ik kan doen. Dus, de laatste jaren is het tot in de politieke mulieus duidelijk geworden dat er een handje-vol Amerikaanse bedrijven heel veel geld verdienen door hun diensten gratis aan te bieden (en eentje in China), maar het geld zelf aan het rollen krijgen door de reclame-machine die ze er op aansluiten.
Los van de enorme inbreuk op onze privacy — waar we in de praktijk eigenlijk niets van merken zolang er geen misbruik is — zou het ons eigenlijk allemaal moeten storen dat we maar gebruik kunnen maken van de aangeboden diensten, en niet rechtstreeks kunnen delen in de winst. (Koop aandelen, mensen. Da's voorlopig het enige dat voor de hand ligt om in de winst de delen, of anders actief meedoen aan de geldwinkel als dat je ding is.) Nu wil ik niet te luid roepen dat het mogelijk is om je kleine beetjes tegoed te bieden volgens hoe braaf je de reclame consumeert, of ze gaan het nog doen ook. Dat zou een volgende etappe in de race naar de bodem inluiden, en ons nog altijd volledig overleveren aan de willekeur van de grote spelers.
Dus, dacht ik. Zou je kunnen een platform ontwerpen, waar je aan deelneemt, en actief aangeeft wat je precies wil vrijgeven, en hoeveel reclame-boodschappen je precies geschikt vind om op te nemen op regelmatige basis. Als je de Million Dollar Homepage herinnert, en het bijvoorbeeld herleidt tot een aanbod van een bepaalde oppervlakte en de belofte dat je dagelijks er naar wil kijken, zou het dan lukken om dat per opbod vrij te geven aan de mensen die marketing-budget maken voor zo'n dingen? Jammer genoeg draait het natuurlijk om het genereren van omzet, uiteindelijk. Of naambekendheid? Ik ken de duistere geheimen van het marketing-wezen niet echt, maar ik snap wel dat 'exposure' alleen tegenwoordig aan belang heeft verloren als je op voorhand al je publiek kan filteren en sturen naar een doelgroep waar een grotere kans bestaat dat je een 'contact' in een 'sale' kan omzetten...
Soit, het is slechts een idee dus. En als je even stilstaat bij dingen van vroeger die zijn gekomen en gegaan, dan moet je weten als zo'n idee maar zou kunnen werken als er van in het begin al een grote gebruikers-groep is, het bijna zeker geen kans op success heeft. Boodschap is om eerst een klein success te kunnen boeken op een kleine schaal. Als dat lukt, is het opnieuw een gok als het wel lukt om daar dan een volgend stapje op voort te kunnen bouwen. Kortom, daar heb ik dan weer geen zin in. Misschien iemand anders.
2021-02-25 20:12
diytotp
![]()
![]()
![]()
![]() [permalink]
[permalink]
Recently, I've got a few things asking to enable two-factor-authentication, and I started using the Google Authenticator app.
I kind of like it. It's a simple enough app, there's a shared secret involved, but it gets pretty close to being airgapped and perfectly forward secure and all of those things. So I got thinking... What would it take to start using it for myself, in those little software things I create now and then...
Is there black magic or stick whittling involved? Nah, a little searching around, and it all appears to be cleanly described in RFC's 6287 and 4226... There has to be a warning here about not rolling your own crypto, but the world of hashing and encrypting really is interesting! I did SHA1 and HMAC before, and Unix' time apparently is UTC... So all you need* is the correct format of URL to put into a QR-code to load up a new key in the app. Then you can use this code to generate the 'current' pass-code for the secret:
github.com/stijnsanders/tools/.../crypto/totp.pas
*: and apparently base32-encoding, HashUtils was missing that...
2020-11-21 15:10
compsciethics
![]()
![]()
![]()
![]()
![]() [permalink]
[permalink]
→ Algemeen Dagblad: Filosoof over digitalisering: geef ict-techneuten net als dokters lessen in ethiek
Update: vreemd, dit artikel lijkt volledig vervangen met een ander intussen. Maar soit, de titel zegt genoeg, de vooruitgang in de toepassingen van software en rekenkracht op maatschappelijk gebied zou hand in hand moeten gaan met een goed ontwikkeld gevoel voor ethiek, een roep die wel her en der in de computerwereld klinkt, zoals hier.
Ik heb dit ook al een tijdje zien aankomen. Computers zijn ontstaan uit de studie naar complexe elektronische schakelingen. Daar kwam ook wiskunde bij van pas om het complexere werk te kunnen omzetten in nulletjes in eentjes. Al snel ging het omgekeerd, en werden de eerste computers al ingezet aan de grenzen van het wiskundige kennisdomein om de berekeningen te doen die door mensen te traag gaan. Een computer maakt ook minder rekenfouten, heb ik me laten vertellen.
Snel foutloos rekenen kwam ook goed bij boekhouden van pas. Naar het schijnt zou IBM veel te danken hebben aan de volkstellingen te mogen doen met ponskaarten. De vooruitgang was niet meer te stoppen en aanbod is vraag jarenlang nauw blijven volgen met betere en kleinere toestellen, die ook goedkoper werden zodat ze vlot het huishouden binnendrongen, en later zelfs de binnenzak.
Toepassingen maken voor het grote publiek komt best wel wat bij kijken. De studie van mens-machine-interactie heeft natuurlijk voor een stuk kunnen voortbouwen op wat al binnen de psychologie werd uitgezocht.
De groei ging zo hard dat het wel eens de verkeerde kant op ging. Zo is de dotcom bubble uiteen gespat, en gaat het niet met de 3D printers zoals analysten hadden gehoopt. Ook dacht men dat in het verlengde van domotica zowat alles op het internet zou aansluiten, maar daar is het — momenteel toch nog — wat te vroeg voor.
Misschien gaat het wel wat te strak met dat aanbod, en als de vraag niet volgt is dat nefast voor de prijs. Als je nu iets wil lanceren online is het eigenlijk vreemd als je er geld voor vraagt. Geld heb je wel nodig, natuurlijk, dus is er een schaduw-economie ontstaan waar je munt kan slaan uit het gedrag van je 'klanten'. De fijne kunst van producten en diensten aanbieden was al goed ontwikkeld in het tijdperk van radio en televisie, maar krijgt nu op het internet wel een heel nieuwe dimensie bij.
Dus net zoals de marketing in het algemeen, dringt het zich onder computer-mensen inderdaad op om ook stil te staan bij ethiek. Je wil zoekresultaten aanpassen aan de wensen en verwachtingen van de gebruiker, maar ethnisch profileren wil je wel vermijden. Moeilijk!
Voorlopig verwacht ik dat Jan Modaal nog even vast zal zitten in een moeras van onduidelijkheid. Met wetten zoals GDPR zijn wel al wat krijtlijnen uitgezet, maar het gevecht tussen de grote spelers speelt in alle stilte boven ons hoofd wel nog altijd af. En eerlijk gezegd vrees ik eerst nog een slingerbeweging in een richting die nadelig is voor wat we als consument kunnen verwachten. Als je een mastodont als Facebook inbeeldt, dat deze zou moeten scheiden in onafhankelijke internationale bedrijven verspreid over de wereld, maar wel een eenvormige gelijkmatige gebruikservaring moeten bieden? Dan moet er al veel duidelijk zijn over dewelke dat dan moet zijn, en er zal niet zo vlot in kunnen geschakeld worden zoals Facebook zelf nu in theorie kan beslissen over hoe hun website ineen zit. Denk maar aan hoe e-mail geössificeerd zit.
2020-09-23 10:31
meanbad
![]()
![]() [permalink]
[permalink]
→ MEAN Stack Considered Harmful
An important read, also reminds me of what I've written here.
Carefull with Gogole Sheet CSV export
2020-06-26 14:18
ggggrgviz
![]()
![]()
![]()
![]()
![]() [permalink]
[permalink]
Ready for another story from the trenches? So image a Google Sheet made by someone else, with all kinds of dat in about 30 columns, of about a few thousand rows. Yes, it's a stretch to keep using Sheets for that, but this data will serve for the analysis for a decent application to manage this with... That probably won't be my team handling that project, but I had to do a quick cross reference of this data with the data in the database of one our current projects. The best way to do cross-checks is get the sheet into a table in the database to run queries. I guess you should be able to import a CSV pretty easily, right? I searched around and found this:
https://docs.google.com/spreadsheets/d/{key}/gviz/tq?tqx=out:csv&sheet={sheet_name}
Which I thought would provide the data in just the way ready for me to import. Wrong. The second column just happened to have codes for all of the items that are numeric for the first few hundreds of items, and then alphanumeric codes. At first I thought the CSV importer was fouling up, but I hadn't looked at the CSV data itself. Turns out this CSV exporter checks the first few lines (or perhaps even only the first one!), guesses the column is numeric, and then just exports an empty value for all non-numeric values in that column!
The code in that column was only in a number of cases needed to uniquely identify the items, so I first was looking for a reason why my cross-match was throwing duplicates in all of the wrong places. Ofcourse. Weep one tear for the time lost, then move on. Take solace in the wisdom gained.
I solved it by using the CSV from the Export menu. I only needed it once so I didn't get a URL for that.
2020-06-05 17:23
cppwebdev
![]()
![]()
![]() [permalink]
[permalink]
→ Quora: Why is C++ not used in web development?
For what it's worth, in creating xxm it feels like I'm trying to create this exact thing except for with the Object Pascal language. Yes, you can do HTTP all by yourself, you can do an ISAPI extension DLL or a Apache httpd module, but you'll still get a strange hybrid between a server service and a web application that has nothing like a platform you can depend on to do the heavy lifting. And, if I'm permitted to speak frankly, in C++ this would be ugly! And probably would need a lot of code to make even the basic things happen. Too bad (Object) Pascal has been called verbose, if you know what you're doing you can write the logic you need in concise readable syntax.
Still what I'm finding in trying to get people to take a look at xxm, they either are unable to disregard the visual RAD form-designer style programming like I do, and don't get that xxm in it's current for is much more like early-days PHP but with the Delphi compiler instead of the script interpreter server-side; or they are fixed in thinking 'the web + Delphi' is all about a data-layer, doomed to only serve plain CRUD requests to and from a front-end layer, and never talk to the user's browser directly. Please! A big strong no on both accounts. Let me explain.
I've always seen — pretty much since FrontPage and DreamWeaver — that if you have a visual designer to manage what to go on a HTML page, you get really ugly code. It'll look the way you want, but a lot of decisions have been made for you. Some with negative consequences for you down the road. And the underlying code is strange and ugly, unneccessarily complex for your website-visitors' browser to work with. I guess modern front-end web-devs must have known this also as I've seen a regression towards working on big chunks of raw coding the last decade. Yes, font-ends are hacking away in CSS and HTML, and not with their bare hands, all kinds of CSS pro-processors and template engines do the heavy lifting behind. So if you know what you're doing, you can have this as well, in a Delphi project. I don't need a form designer, I make the page-builder first with dummy data, and run it in the browser. Don't forget, hitting F5 in the browser to an xxm website running over a development-handler, fires up the Delphi compiler there and then. Edit→Save→Refresh→Repeat
Then there's the other thing. If you start a conversation about webservers and Delphi, bam there's DataSnap. Strange. Is it because I'm strongly dys-convinced about ORM's? (Reminder to self: still have to write that grand essay about what's bad about ORM's.) Yeah sure, if you have things that use RTTI to serialize your data-objects in some way, you can easily use one of the available options to serve it over some web-server and bam you can call it REST and get away with it. But this is a completely different thing than having a full blown web-application serve from something you created! Complete with images and stylesheets. And yes you can have both🤯 from the same web-server-service🤯. I've had people walk away, unable to believe me. It still feels like it's a case of opening your mind to be able to see it.
Anyway, sorry about the rant. I'm getting tired of trying to find the people that combine real web dev with Delphi for the server side. Yes there are a lot of new things that compile (Object) Pascal to JavaScript, but that's another story. That's nice for the front-end. But if you dig deeper, or want to reach the people that you can't offload your gargantuan client-side workhorse to, please think about xxm. Give it a try, see if you can make it work. If you want an example of what I'm talking about, take a look at feeder or tx.
Feeder: support WordPress API "wp/v2/posts"
2019-09-14 23:40
wpv2posts
![]()
![]()
![]()
![]() [permalink]
[permalink]
Is it normal that a WordPress website serves it full "https://api.w.org/" REST API from the home page (e.g. https://foreignpolicy.com/)?
I just happed to notice <link rel="https://api.w.org/" href="..."> while I was looking for an RSS url. So I had to have a closer look. It looks like it's open for anyone to POST new posts to /wp/v2/posts?!
Anyway, I've created support for it in feeder/eater...
PDF-web: tried forms but nought
2019-08-09 18:40
pdfweb
![]()
![]()
![]() [permalink]
[permalink]
A while ago I thought, since modern browsers show you PDF documents conveniently in the same window, could you make links work and have a dynamic webside that serves PDF pages?
But yes ofcourse you can. Then I also recalled it's possible for a PDF document to have form fields you can fill in. I tried, but the PDF viewers in modern browsers don't appear to support those. (Yet? Give me a ring if they ever do and I'll see what I can do.)
Update: Oh, what's this? Looks like they're working on it...
2019-07-19 21:11
jmap
![]()
![]()
![]() [permalink]
[permalink]
→ E-mail over HTTP (2012)
Ofcourse the magnificent people that are already behind the internet (that beefed-up telegraph with funky terminals) have been working silently on exactly this in general, but completely different in the details: RFC8620: JMAP
2019-07-14 00:54
pdfweb
![]()
![]()
![]()
![]() [permalink]
[permalink]
I had an idea. PDF nowadays open right in the same browser window. We can thank the steady progress of the JavaScript ecosystem to make this possible. And also more secure, if I understood correctly.
Also, in a PDF you can mark text or a rectangle as a hyper-link. So it should be possible to create a dynamic website that uses PDF instead of HTML, right? One way of looking at it is that PostScript in PDF is a way to layout things on your page just like HTML is.
Anyway, I had to see how much of work it would take to make a proof-of-concept. So here it is, it's not much on the dynamic side, but it's a site that opens to a PDF, and links to another page of the same site.
→ https://github.com/stijnsanders/pdfweb
2019-03-12 23:27
qoudkranten
![]()
![]()
![]()
![]()
![]() [permalink]
[permalink]
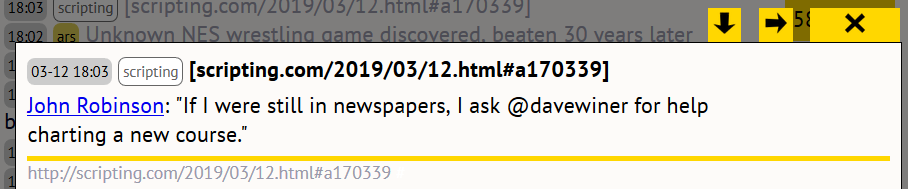
Ocharme de kranten, wat hebben ze het moeilijk. Nog een slachtoffer van het digitale tijdperk? Ik ben het nog niet zo zeker. Je moet je altijd aanpassen aan de tijd van tegenwoordig. En met die tijd van tegenwoordig is iets ernstig aan de hand. Laatst las ik iets in de trand van "internet is geen nuance-machine"... Dat laat weinig aan de verbeelding over. Jammer genoeg klopt dat wel. Als je een omgeving hebt waar extreme meningen meer weerklank vinden, dan loopt het vroeg of laat wel eens fout. Intussen wordt pijnlijk duidelijk dat het ook voor de rest van ons tot gevolgen kan leiden.
Maar wat moeten de kranten dan doen? De formule van een goedkoop gedrukt wegwerp-ding te kopen met de dingen van gisteren op, is goed en wel achterhaald. Het vertalen naar een online-verhaal waar je de titels toont en de mensen laat betalen om verder te lezen, pakt gewoon niet. Niet in een abonnement-verhaal, niet met micro-payments per artikel. En al helemaal niet als je denkt dat je kan meedoen op dit nieuwe platform dat is gegroeid uit openheid, maar geen links naar de specifieke artikels op je website wil...
Soms lijkt het dat ze enkel het kosten-plaatje zien, en niet te ver durven kijken. Als ze durven flemen met meer sensatie-beluste insteek, dan gaat het inhoudelijke snel achteruit en trek je misschien niet het publiek aan dat je eigenlijk wil hebben. Ik denk dat ze net terug naar de essentie van de journalistiek moeten teruggrijpen. Vroeger was een krant het eind-product van een goed geölied team dat elk zijn essentiële taak vervulde, en net zo'n pipelines krijgen het overal in deze moderne tijd zwaar te verduren. Dus ook hier: skip the middle man. Ik weet dat nieuws voortvloeit uit een redactie. Als journalist moet je actief op de hoogte blijven van wat er staat te gebeuren. Moet je weten hoe je de ontwikkelingen kan bevestigd krijgen, waar je meer kan weten over de keerzijde van de medaille. Waar je andere perspectieven kan raadplegen en precies de nodige nuance kan vinden en aanbrengen.
Dit zit allemaal netjes verborgen achter wat wij uiteindelijk te lezen krijgen als consument. Misschien moet dat maar eens veranderen. Ik wil de kwelling en hitte van een redactie wel eens zien afspringen van een informatie-platform waar je meer dan het huidige nieuws te verwerken krijgt. Alles dat leeft bij de mensen of over de telex binnenkomt, moet toch worden gefilterd, gekaderd, bevestigd. Wij zijn niet onnozel. We kunnen dat aan. Meer nog, misschien moet je net de mensen betrekken er in. Lijkt misschien een vreemd voorstel als je ziet wat er doorgaans in de comentaarrubriek binnen komt, maar hier kan je misschien een verdien-model in je voordeel gebruiken. Je laat een gratis ingangs-niveau niet zomaar aanbrengen, maar mensen die bewezen hebben dat ze iets waardevols te bieden hebben luister je wel naar. Of dat waardevols deel uitmaakt van het omzetcijfer is een andere vraag, maar dat is voor een andere keer.
Ik beeld me dus in dat je op een centrale plek alles te zien krijgt. Zelfs al is dat aangetoond een leugen, of nog in afwachting van een bevestiging. Stel dat er iets binnenkomt dat te sterk of te eenzijdig is opgesteld, kan het worden gevlagd. Kan je het toetsen met meer gematigde versies en of die dan niets van de essentie verliezen. Groepeer de ontwikkelingen per oorlogsgebied, ramp of regio en laat de mensen mee beslissen of een bij-verschijnsel een nieuw onderwerp moet worden. Lok de mensen met een lijst van wat ze willen zien, maar hou ze bij met een lijst van dingen die daaraan toevoegen en de nuances die eromtrend spelen, en je kijk op de zaken verruimen.
Vreemd genoeg lijken mij het dingen die allemaal al bestaan. Sites zoals slashdot.org en stackoverflow.com werken al jaren zo. Hoewel ze niet zozeer op een verdienmodel draaien, gaan ze ook niet bepaald om de brede actualiteit. Wel zijn ze van en voor een specifiek publiek die weet waar het om gaat. Misschien dat daarom wel eens naar wikipedia.org wordt verwezen, waar je ook een kleiner specifiek publiek hebt dat over de inhoud waakt terwijl het in theorie wel open staan voor het brede publiek. Van dezelfde mensen is er iets met nieuws, maar ik ga er van uit dat deze niet zo alles-omvattend en doorgezet kan zijn als je zou kunnen verwachten van een redactie met professionele journalisten.
In afwachting van het duidelijk wordt waar ze naartoe willen, blijf ik lekker free-loaden op de RSS feeds die ik kan vinden. Zolang ik de nodige achtergrond kan oppikken van de dingen waar de mensen het over hebben, en ik in de loop van de dag al kan gissen waar het in het avondjournaal over zal gaan, ben ik al tevreden.
Update: Als ik dit lees zitten ze mogelijk ook op een vergelijkbaar spoor...
Update bus: Zelfs internationaal denken ze er aan blijkbaar... En een van de grondleggers van blogs en RSS zegt het...
2019-02-03 21:51
rasphone
![]()
![]()
![]()
![]() [permalink]
[permalink]
Dit is er eentje om te onthouden. Ik had problemen met de VPN connectie naar het werk. Het is te zeggen, het werkte vlot en naar behoren op mijn vorige laptop. Ik koop me na x jaren eens een nieuwe laptop, neem de instellingen over, noppes. Waarom precies is me niet duidelijk aan de error. In de event log vind ik RasSstp die zegt dat het of een timeout of een certificaat-probleem is. Dus was ik al de certificate (stores! wist ik veel of het de computer of service of persoonlijke store is) aan het uitpluizen voor een eventueel verschil. Ik had zelfs al netsh ras set tracing * enabled gevonden maar daar vond ik helemaal niets in terug... En dan kom ik plots toevallig langs deze (lap, vergeten de URL van waar ik het zag bij te houden):
C:\Users\%USERNAME%\AppData\Roaming\Microsoft\Network\Connections\Pbk\rasphone.pbk
Blijkt daar niet alleen precies inderdaad een cruciaal verschilletje te zitten in één van de honderden parametertjes daar, blijkt ook dat je gewoon extra files in die folder kan zetten en ze verschijnen auto-magisch in het netwerk-menu onder het icoon op de taakbalk. En voila, probleem geflikskts.
Open source is nice, but is the protocol also open (enough)?
2019-01-15 08:57
openproto
![]()
![]()
![]()
![]()
![]() [permalink]
[permalink]
See, this is something I'm very very worried about: things like Bitcoin — big public successful open-source projects — have the appearance of being complete open and public, but the protocol isn't really.
When I was first looking into Bitcoin and learning what it is about, really, I'm quite sure this can only have originated out of a tightly connected bunch of people that were very serious about 'disconnecting' from anything vaguely institutional. Any structure set up by people to govern any kind of transactions between them, has the tendency to limit liberties of people, for the people taking part in the system and sometimes also for those that don't. So it's only natural that Bitcoin at its code is a peer-to-peer protocol.
But. How do people that value anonymity and independence from any system, even get to find each-other and communicate to build things together? Well, the internet of course. But perhaps more importantly — and also since long before the internet — cryptography. Encoding messages so that only the one with the (correct) key can decode and read the message, helps to reduce the cloak-and-dagger stuff to exchanging these keys, and enables to send messages in the open. To the uninitiated onlooker it looks like a meaningless block of code, and in a sense it's exactly that. Unless you what to do with it, and have the key — or would like to have it.
Another use of encoded messages is proving it's really you that originally encoded a message. It's what's behind the Merkle tree that the blockchain runs on. That way the entire trail of transactions is out there in the open, all signed with safely stored private keys. The reader can verify with the public keys, and in fact these verifications buzz around the network and are used to supervise the current state of the blockchain, building a consensus. Sometimes two groups disagree and the chain forks, but that's another story.
The protocol, or the agreement of how to put this into bits and bytes in network packets, can get quite complex. It needs to be really tight and dependable from the get-go, see the article I linked to above. You could write it all down and still have nothing that works, so what typically happens is you create a program that does it and test it to see how it behaves. In this case it's a peer-to-peer networking program so you distribute it among your peers.
But when things get serious, you really need the protocol written out at some point. If you try that and can't figure out any more what really happens, you're in trouble. The protocol could help other people to create programs that do the same, if they would want to. This was something the early internet was all about: people got together to talk about "How are we going to do things?" and then several people went out and did it. And could interoperate just fine. (Or worked out their differences. In the best case.) It typically resulted in clean and clear protocols with the essence up front and a clear path to some additional things.
The existence of the open-source software culture it another story altogether, but I'm very worried it is starting to erode the requirement for clean protocols more and more. If people think "if we can't find out how the protocol exactly works, we can just copy the source of the original client/server" nobody will take the time to guard how the protocol behaves in corner cases and inadvertently backdoors will get left open, ready for use by people with bad intent.
Don't panic: Bitcoin's usual pre-end-of-year dip is here.
2018-11-23 00:29
btceoy
![]()
![]()
![]()
![]() [permalink]
[permalink]
Don't worry. The price is going down a bit, yes. But I think there's no reason for massive public panic and the cyber-world's equivalent of a run on the bank. The holiday season is here. Black Friday. We need presents for the family, and that costs money. We may have chosen to put the value of our earnings into this new thing designed especially for that, and now need to convert some back to good old local currency, so it probably pushes the exchange rate a bit down. It may even be a good sign of institutionalisation that automated agents kick in and join in on the selling, pushing rates even further down, dramatically so. But it's best for all of us if that's only a marginal effect. If I were speculating, I would guess it would start to look like a buying opportunity, if I could statistically detect when the bottom would come into view, but I am not. Actually I don't care. But since we're guessing, I guess things will bounce back in January. It did last January. Perhaps it won't get to the same levels as we had up till before this dip, but that's OK. If it's all rather stable for a few months, that would be good, but if it follows real events in the real world, that's also good. It's just normal. I'm not worrying. Perhaps next year we'll be paying Christmas gifts in bitcoin. (Though I wouldn't put money on that...)
Browsers with less and less UI...
2018-10-05 17:19
browserslessui
![]()
![]()
![]() [permalink]
[permalink]
Here's a wicked idea: With browsers trying to have less and less UI, the line of death getting more and more important to help guard your safety, and some even contemplating seeing the address bar as a nuisance — who types a full URL there nowadays anyways? — what if there was a browser that always opens fully full screen. No need for F11. You still need a back and a refresh button, and something that gives access to all the rest like settings, stored page addresses, and if you really really need it, the address of the current page. But it is hidden from view most of the time, except when you make a certain gesture, like a small counter-clock-rotation. It should look different enough so it contrasts with the page, and should be different every time, so it isn't corruptable by any webpage. And even then should be obviously not part of the page.
And people need to find it intuitive and self-explanatory.
Oh never mind.
ECB should plan to issue a digital currency!
2018-09-18 00:07
nodraghi
![]()
![]()
![]()
![]()
![]() [permalink]
[permalink]
→ Reuters: ECB has no plan to issue digital currency: Draghi
Here's an idea. Just an idea, floating it here to see what you think, no concrete plans yet. The internet should float a new digital currency. "Wait, what? We have Bitcoin/Litecoin/Ether/... already, are those not internet's digical currencies?" I hear you think. Well, no. They're intended to perhaps become currency, but that kind-of totally failed. The world wasn't ready for Bitcoin when it hit us, and all the nice plans kind of prescribed to one day use bitcoin as currency, but as the hype and dust are now somewhat settling, it's clearly unfit for that purpose. It's still great at what it does though, and it could perhaps serve really well as something like gold: something that holds value you can buy and sell and will most probably get bought and sold in the forseeable future, according to current market behaviours. And there's the blockchain which it all runs on, it's a great proof-of-concept of a public ledger that some industrial settings could greatly benefit from, who knows perhaps in a slow movement from the fortified castle paradigm to the zero-trust concept.
But as a currency? No. Currency is allergic to strong ups and downs in the inherent value. "Didn't we have all this already, the US dollar doesn't have inherent value as well, since we've let go of the Gold Standard?" Well, no. The price of gold may now be free-floating, but since the entire US economy and a sizable part of the world's economy is running on US dollars, you could consider the entire economy as what's carrying the real value of all those dollars. I'm oversimplifying here, but some big large-scale economic metrics appear to work reversed for the US-dollar because of this. A currency as we know them now also had a central body that goversn both the internal use of it, and the powers that exert on it from outside, other currencies and macro-economic movements.
So here's my idea: because Europe is looking to do something about copyright on the web, and newspapers — and perhaps journalism in general — are struggling, something like the European Union should float a digital currency, specifically to make micro-transactions on the web. And I really mean micro. Listening to a song? Bam, something tiny moves from your online wallet to the musician(s). Viewing a video? Bam, something tiny moves from your wallet to actors, directors, lighters, screenwriters and background-painters. Read an article? Bam, you get the idea. How much? How many articles are in an avarage newpaper? How much does a regular newspaper cost? Calculate back from that to get a good first unit of value.
As an alternative way of payment, it could complement the Euro, and only later move up the ladder if there's a base of users with accustomedness. But to get there some important details need to be set up just right. It will need a governing something, but I wouldn't hand it over to Frankfurt. The time is right to involve the people. Bitcoin is doing just right without central oversight, but the required checks and balances need to be baked in. Anything new like this should also be design 'of and for the people'.It will need its proper legislation to get to serve as anything official, an get it accepted as a bearer of value, but by limiting who can exchange how much to and from real currency, for example a weekly global limit on conversion, could dampen the risk of large-scale mutations induced by panic. Or by limiting the maximum amount you could hold per user or per device or per account, could limit the importance of this new stream of cash in regard with the entire economy.
Also as an internet-centric application, every user wanting to participate needs to run the software, but it should be entirely open so each of us can govern that our security and privacy is catered for. Only then it's ready for designing the conduit with which you let the websites you visit know what credit you provide when consuming songs and articles. There needs to be something like a public ledger, since that would make it a new skool digital currency, but requiring every mobile device to keep a full copy of the ever growing full ledger is absurd. And it is also limiting the maximal number of transactions that can get processed in limited time, so that needs to get decentralised as well. I'm not sure how, but I'm sure there are people smarter than me that have been deep enough into the theoreticals that could draft what it takes.
But I'm just dreaming aloud here. Innovation hurts and is hard work. And there are always those that don't want anybody to challenge the status quo.
Update: look, look, this is also about something like that!
2018-08-08 00:55
feeder
![]()
![]()
![]() [permalink]
[permalink]
I've been using RSS/Atom feeds on and off since I've learned about them. A long time ago, Google had a nice feed reader, but decided to discontinue it. Users were left to search something new, and I settled on The Old Reader, combined with gReader since I had a smartphone, and all was well. For a while. After some time you notice you still get disturbed by some tiny issues you can't seem to get to go away, either with tweaking the configuration or with Stylus. So what does a developer do? Start to think about developing their own solution. Then plan to develop their own solution. Then develop their own solution. So I'm somewhat proud to present this little thing I've been tinkering on in off-hours the last month:
→ github.com/stijnsanders/feeder
I have a live version to try out here: http://yoy.be/home/feeder/ but it uses the neighbouring instance of tx for authentication. I should enable Google/Facebook/Github OAuth things instead, but finding out how that works is a few items lower on my wish-list (of things I wished I had the time to put into).
I wanted a feed reader without the extra's. I wanted to mark items as read that move out of view by scrolling down, and plays somewhat nice with the surrounding HTML and the browser. For now I like how it works. There's an issue with emoji's that apparently get eaten by UTF8Decode, but that could be a bug that got solved since good old Delphi 7. But now that Delphi has a community edition, I think I should bring most if not all of my other projects to this version instead of sticking to Delphi 7... But that's another story. (One you might notice some time in the future on my Delphi RSS feed...)
StackOverFlow/Delphi: new blood?
2018-07-12 21:30
sodnewbies
![]()
![]()
![]() [permalink]
[permalink]
→ Stack Overflow — Newest 'delphi' questions
Am I seeing this correctly? I've been following this page somewhat less closely lately, but the majority of new questions is by people with not too high of a reputation score. And that's actually a good thing. Let me explain:
A while ago it looked like we were 'past StackOverflow peak'. StackOverflow started as an alternative to outperform all other question-and-answer sites for techies, by having a really well developed reputation system that allows a community to self-regulate. And it did. Both the reputation-system created a really fine repository of good questions and good answers, and all other question-and-answer websites were oblitherated (at least from the google top results on typical search-queries).
A few years later, StackOverflow appeared to struggle with having lost it's reason d'être: people with actual questions would easily mistake StackOverflow as a forum and saw most questions rapidly closed and reprimanded for not attaining an expected level of quality the community would hold to. This is a bad deal for newcomers and in general a source of bad feelings. They know about this over at StackOverflow. And have committed to take action. I haven't kept up to speed about what they're exactly plannig to do, but it could already be working.
Specifically for the questions tagged 'delphi', it's not only good that this way more people that just started collecting a reputation saldo, are posting valid questions and are getting helpful responses; I also think you can derive from it that more people are getting into Delphi. It's not up to me to tell whether that's in part because the most recent Delphi versions also successfully target mobile platforms, but if it's true I'm glad to know more people are about to experience the solidness of the Delphi eco-system, both in tooling and available components, and in solidity and reliability of your final result you're offering your users.
2018-07-06 21:29
whatsyourstyle
![]()
![]() [permalink]
[permalink]
→ Firefox and Chrome Pull Popular Browser Extension Stylish From Their Stores After Report Claimed It Logs and Shares Browsing History, Credentials — Slashdot
→ “Stylish” extension with 2M downloads banned for tracking every site visit — Ars Technica
Oh, what's this? Note to self: switch to Stylus, (also here and here)