Delphi 64-bits: set your local variables!
2026-02-14 10:43
d64lvi
![]()
![]()
![]()
![]()
![]() [permalink]
[permalink]
I'm relatively new to programming for the 64-bits platform, and I ran into the same thing twice now, so I feel I need to write about this. This last time, it even first showed up as an exception that occurred with the release build only, not the debug build! But it showed up consistently, so it was something I could investigate. I found out the specific exception only occurred with the 'Optimization' compiler switch enabled. Apparently 'modern' Delphi has the 'Optimization' switch set to off in default 'Debug' configurations, and on in default 'Release" configurations.
'Modern' Delphi apparently also has 'Use debug DCUs' on for both 'Debug' and 'Release', which I very much regret. Most especially because when I introduce newlings to the Delphi debugger, we invariably drop into a core .pas-file, either causing confusion, or the need for an explanation of what that is and why you'd better never make changes there. Or also what's the relation to the program you're building on one side, and the resulting compiled binary code on the other side. Any way breaking away from working with the debugger for the remainder of the lesson.
What I want to warn about is that apparently the 64-bit compiler no longer provides the internal scaffolding to clear the memory of the local variables in procedures and functions. It also doesn't warn that you're using an unintialized value (1). In my case I've seen bugs appear just by switching from 32-bits to 64-bits, so be careful to always have an assignment to local variables before using them. Even if it's integers to zero and booleans to false. (Strings on the other hand, because of them being a pointer-type by nature, are zeroed for you.)
(1) The compiler does warn about you not using a value set to a local variable. And there's also a difference there between 32-bits and 64-bits compiling there. If you have a superfluous assignment to set a default value at the beginning, and the following code also sets a value in all branches of ifs and cases, I've found that the 32-bits compiler warns less about the unused assignment than the 64-bits compiler does. Perhaps because it's silently de-duplicating the assignments it's doing behind the scenes anyway? It's a minor inconvenience, but one I can live with, and one that reminds me to check if all local values get an initial value by my code.
2025-05-20 22:06
allsorts700
![]()
![]()
![]()
![]() [permalink]
[permalink]
→ AllSorts (github release...)
Shell extension "AllSorts" had been switched back from Lazarus to Delphi Community Edition some time ago, but this also allows me to add something that I was thinking of for a while, but hadn't taken the time to get it done: an option to 'paste into' a new file any text content currently on the clipboard and have explorer switch to editing this new file, just like you get with the 'new...' content menu options.
And lo and behold: it's just one API call away! (Well, two actually, I need the path converted to an item-id-list first...) But it looks like it works (and it looks like it'll be one of those things I'll need a few times a day, just like the "Copy UNC" option!)
2021-11-24 20:38
ildasm
![]()
![]()
![]()
![]() [permalink]
[permalink]
Hier is een gek ideetje: zou ik met ilasm.exe sneller dingen voor dotnet kunnen op basis van mijn eigen taal, dan dat ik me in de dingen rond CodeDom en Roslyn zou moeten inwerken? Stel, ik doe kleine dingetjes in C#, kijk met ildasm.exe hoe die IL er uit ziet en die doe ik na. Alleen, veel optimizing moet ik niet verwachten waarschijnlijk. Behalve /optimize die blijkbaar wat instructies kan verkorten, en eventuele achter-de-feiten optimalisatie van de JIT. Maar misschien zou het genoeg zijn om de bootstrappen? En/of beter de rest te snappen eenmaal ik verder raak met het echte compilerwerk. (Of zou ik toch eerst nog eens LLVM proberen?) Ik was voorzichtig begonnen aan een 'Pascal code gen', maar daar komt meer bij kijken dan ik had kunnen denken. En dan doe ik dat al om uit de weg te blijven van register allocation...
Quick, write it down: just another CPU design idea
2021-05-05 23:57
cpuidea
![]()
![]() [permalink]
[permalink]
Ever since learning about the Mill architecture, and watching an excellent series of MIT 6.004 lectures by Chris Terman (I can't find them on Youtube any more! But there are newer versions of 6.004 online which probably are great as well.) and reading up on what's new about x64 and RISC-V and ARM, from time to time my mind wanders if you could go crazy and design yet another CPU design that does novel things with the umptillions of available transistors and not have the downsides of the currently popular CPU's.
So here's an idea I just need to write out of my system, and let you have a look so you can see if there's anything there at all. Modern CPU's use virtual registers to have hyperthreading and speculative execution, and push whatever ahead in the hope it was the right branch to make pipelining work better for the workload at hand. The Mill architecture would handle that a little different and fill the pipeline just with more concurrent threads and interleave those. (At least that's how I understood what would be going on.)
What if you design a CPU so that it also takes in a larger set of streams of instructions, also using a bank of virtual registers that get alotted to these streams, but also have hot memory just like the closest cache is, but use that for the stack. Ideally you could expect programs to keep the current stack-frame fit within one or a few kilobytes, and by having a larger number of streams you could avoid having to switch this stack along with all the rest on context changes (by the OS). Switching the stack and overflowing the stack to and from memory is something that will have to happen, so you'll have decent support for that, but if you're after speed you'll try to avoid it as much as possible.
Let's have some numbers just to get a clearer mental picture. Let's say a core has support for 256 streams of instructions. If the work for them is pipe-lines across the rest of the core, addressing them would take 8 bits, so you would see a band of 8 lines pipe-lined to everything everywhere. It's not even required to have 256 instruction decoders, and sub-groups of streams could share commen instruction decoders, but depending on the instruction set design itself, this could turn out to be the bottleneck, but let's find that out with further design and research.
Let's say each stream gets 4KiB of hot stack memory, in total is 1MiB which is not unrealistic to have in a modern code nowadays, if I understood that correctly. This special memory could have extra lines so it automatically flows over into system's memory if the local stack index rolls over, which perhaps could also help with loading and flushing stack data on context changes.
With instruction fetching, stack handling and these streams doing their thing with alotted virtual registers, there's a lot covered, but the ofcourse the sweet magic happens in ALU's and related things, so down the pipe-line, according to what instruction decoding prescribes, the streams queue up to get one of the available ALU's to handle an operation.
This would be a point at which you start on a real design in a simulator, but that's where my knowledge is stronger than my experience. I just decide to start writing things down (right here, right now), let it simmer a bit and maybe pickup starting a first attempt sometime later. If you see what a former attempt like plasm ("play assembler") looks, don't get your hopes up too much. For now it's good that I wrote the core idea down here. If I ever get down to it again and get something working, you'll read it here. Sometime later.
205B random strings and no 'Delphi'
2021-02-28 18:48
randomdelphi
![]()
![]()
![]()
![]() [permalink]
[permalink]
→ Delphi-PRAXiS: Can Delphi randomize string 'Delphi'?
Ah, that takes me back. A while ago at work I got someone baffled by this statement: It is said that a thousand monkeys banging away on keyboards could at some moment in infinite time produce the complete work of Shakespeare (and that the combined internet forums are a living counter-proof). Now if you search online you can find an XML download of the combined works of Shakespeare, so it's not hard to find the relative occurance of each letter of the alphabet. One can guess this will have rougly the same values per letter as the total of the English language. So, then, if you take 'random' by its definition, and the monkey's produce text at 1/26 probability for each letter in the alphabet, therefore they'll never reach a point in time where they (re)produce the works Shakespeare.
Now, I'm not a real philosopher, or a statistician, so my thesis could be complete fiction and based on nothing, but sometimes you really got to take a lesson from practice. In theory, in infinite time, it's ofcourse possible that something really really inherently possible could emerge out of a random system, but there are characteristigs to anything random, and there are exponential things at play that soon but experimantal set-ups like with the link above, that they probably would produce the expected outcome in a time-span that exceeds the number of years we've got left before the sun sheds its outer layers and devours the earth, complete with a set of silicon-based machines churning away at putting a series of random characters in sequence and comparing them of some neat stories of a long gone English playwright.
Google is too big! Time to split it up in pieces.
2020-12-18 23:42
splitgoog
![]()
![]()
![]() [permalink]
[permalink]
I've tought and written before about splitting up Microsoft. With the recent lawsuits against Google, there's talk about splitting up Google. But how? My mind starts to wonder. If you would ask me, this is what I would say, based on what I know (which may not be the full picture, but I'm just trying to do the same to Google what I did to Microsoft before, let's see where it takes us.)
Department: Advertising
Products: online ads and banners
Revenue: price per exposure
Let's start with the cash cow. I know there's a bit if 'advertising' tied into 'selling' keywords with the search results, but I'm not considering that in this department. So specifically the online ads and banners shown on all kinds of websites, should separate into something independent. The sweet talk that proclaimed benefit from keeping it tied into the big mix is about being able to offer you more relevant ads, but we know what that means. Your e-mails and search queries go through a farm of computer centers, and you get advertisements for the stuff you just bought. (Or a brand of dental prosthetics you're orthodontist doesn't even work with...) So back to basics, one trustworthy entity you can call upon to fill a side-bar of your website to show a marketing message of some other company (that's not on your black-list). (Or perhaps that is on your white-list, but I guess you would have to agree to review newcomers soon enough or your percentage might suffer, or something...)
Department: Android
Products: anything Android
Revenue: licensing
Open source and big companies are a complicated subject. If we stick to the basics, and perhaps compare to something different but somewhat similar, I still think an independant corporate identity could be the steward of the Android project and sell licenses to get permission to use the Android name, and get a hand on a curated build by the central authority of the project. If you really want, you can fork the project and roll it all yourself, but if you pay a reasonable price, you could get feedback if you're doing it right, get certifiers from the central authority to guarantee you the binding with your hardware devices is just right and is future-proofed for at least a version or three.
Department: Chromium
Products: Chrome, ChromeOS, (Fuchsia?)
Revenue: not for profit foundation
Google once decided the best it could do to be sure people could get the best possible access to their web services, is provide the best possible browser. It took an available HTML rendering engine that was the easiest to adapt (WebKit), an advanced new JavaScript engine that was beating benchmarks by compiling the hottest bits of code of a page (V8), did all the new things the others did also (tabbing, accept more than URL's in the address box), added sandboxing for security and a brute but effective technique to protect against a minor problem browsers sufferd from back then (process crashes, with a process per tab, only a tab crashes). It was a success. It may have been the beginning of the end for Microsoft's Internet Explorer, but it did re-heat the browser competition. It's sad maybe that Mozilla is having difficulty keeping up of late, but the fact that they're a not-for-profit, is something I guess would be a good setting for everything Chrome when Google would split. Microsoft, Brave, Apple (Safari), could all benifit from a central authority to work with and decide over important things about the internals of the generic browser experience. It should keep close ties to Mozilla and web-standards-workgroups, and perhaps even merge. But this may be wishful thinking on my part. There's also a thing called ChromeOS and Fuchsia, and I'm not sure if a full fledged operating system (built around a browser) would fit into this, but it might. Look at Linux, that's doing great as a set of non-profits, but with corporate backing here and there, right?
Department: Search engine
Products: search engine
Revenue: keywords auctioning
There's this story online of an ex-employee of a search service provider, that knew the end was near when fellow employees were using Google themselves. Search for it online, you'll find it. Google cut out the middle man and the search service market evaporated. It started with a thing called PageRank, but what it did was offer better results to anyone's search queries. If you take all the text on the web, and search for bits of text, you're off to one side of the ideal result set. If you think you could catalog all of the web in an extensive category system, you end up on the other side of the ideal result set. (And put a lot of effort in for limited returns.) You could try and build something intelligent that organically aims at this center sweet spot, but remember Goodhart's law. If you succeed, your new system will get gamed. In other words, SEO was born.
So the search engine part of Google living on its own could and should still offer to show 'paid for' search results on the keywords stakeholders select and/or organic statistics indicate as good candidates. Since there's money envolved, the engine needs to be transparent (of the crystal clear kind). In tune with the new spirit, it should be based on anonymity and respect privacy to a high degree. Even so, it could and should still actively promote societal inclusivity and combat (internationally?) criminal behaviour like enciting violence or popular misleading.
Department: Productivity Software
Products: G-Suite apps
Revenue: subscriptions
It will need a new name though. I guess it started with GMail (which itself may be a response to Outlook Web Access) that hit a sweet spot for people in search of a low bar to clear to get started with e-mail, and also with established users that appreciate improved defaults in e-mail handling. (Yes, Outlook has a threaded conversation view, but not by default, I remember it was buried in the custom column sort group view something in Outlook 2000.) A logical extension was a calendar and the rest of the usual apps in an office suite typical attachments are made with (word-processor, spreadsheet, slide show). That it would all get delivered through the browser, now looks like an evolution that would have happened anyway. But it may be easy to take heavy-hitting modern browsers for granted these days. Anyway, their office suite has managed to catch up fast and is almost feature complete with most other office suites out there.
Department: Cloud Services
Products: anything cloud
Revenue: pay for what you use
It takes a lot of resources and effort to put up all this machinery in data centers to churn away and convert network traffic to and from storage. It takes a specific organisation to make it all work, and it's inceasingly done with a distance to what it is you're clients are actually up to. As a provider you've got a set of virtual machines running, and everything everywhere has the hell encrypted out of it. In the ideal case, you couldn't even get to know what you're clients are actually working on if you really wanted to, by design. (Though some find this too ideal.) What I noticed is that much of the cloud offerings out there like AWS and Microsoft Azure, are getting a lot of parity: for everything cloud, there's a roughly similar offering from each of the providers. In an ideal world, you can mix and match to your benifit, but since they're still tied to the data-centers they run in, we're still stuck in one of the silo's unless we pay extra to set up a dedicated link between them.
Department: Research
Products: ?
Revenue: ?
Being Google, the research that's been done ends up all over the place, or nowhere (Wave? Glass?). They start a thing called SPDY (pronounced "speedy"), and it ends up parts in HTTP 3 and part in a kind-of successor to TCP? They're building cars, and also a boat, or is it a barge?
To their credit, it's actually OK that Alphabet Inc. was created as a group with Google as a member. It opens up the endeavours thet get 'promoted' into members of Alphabet of their own for a possible future on their own, or under another corporate parent. One of these is "X", which apparently handles any undefined research going on. Anyway, things like that may be going on in any large young tech firm, so why not out of one of the newly formed ex-Google-chunks outline above.
And I'm sure I forgot some things that Google is also doing, but I think I've listed the most important things here.
What if they replaced Windows with Microsoft Linux...
2020-10-11 20:26
winmslinux
![]()
![]() [permalink]
[permalink]
→ What if they replaced Windows with Microsoft Linux
Hmm, in the very far future, sure, why not. But right now, it may be a little harder than these people make it look like. So, where are we now and what would it take? I'll do some projections here based on what I personally feel and think, so I may be far off, but I hope I can make some points some people may be overlooking in this matter...
We've got WSL which was a great first step in the right direction. The most important thing here, and I guess it follows from the work that was done to get Docker working on Windows, is that there's deep deep down in the mechanics of the kernal, made an opening into the very fiber of the very thing that makes Windows Windows, and a base into the task scheduler so it could work with both the heavy-handed old-style Windows processes, and the lighter, moderner Linux-like processes. (I believe it was chosen to call them pico-processes because I guess at that level you'll not really want to get tied to something specific like Linux there and then...) What I really think is the most important that this serves as a precedent, that the kernel team is listening and willing to budge in any direction at all. So yes perhaps into a hybrid model where Windows allows a little more *nix very close to it's internals, and move from there to a little more and more of this and a little less and less of the old until it's all fine and ready to move up into an emulation layer. At this point they should have seen this coming, Windows 95 had to be able to run 16-bit applications for DOS, and ran 'Windows on Windows' 16-bit application with a translation layer that would convert all the calls to the underlying system 32-bits system. So, if you're on Windows, check your machine now for C:\Windows\SysWOW64, yes there's another emulation layer your 32-bits applications use to get work done on the underlying 64-bits system. I guess they're very hard at work as we speak to have a "Windows x64 on Windows ARM" as we speak, I've noticed some news items about that here and there recently.
(Which I regret a little bit, to be honest. I guess things could get a lot smoother to first have a "Windows ARM on Windows x64" sub-system and start promoting the developer tools to get your current applications already running in (fake) ARM and have the plain user completely oblivious. Performance will probably be comparable, and the gain you'd get when you finally get a hand on Windows-ready ARM hardware would be even greater because they've already prepared for ARM... But this may be all wishful thinking on my part, and a hard sell to management that need to get to maximum success with minimal investment...)
WSL 2 is another step in this direction, it lets go of talking the speach a kernel would, and talks all like 'system' what a kernel itself understands. It's only a step though, and what I'm really looking forward to is having a full-on Linux application play nice with the Windows graphical environment. There's a lot of differences to overcome there to make it happen, but it would open the way for the next steps. If there's a way to have both side by side, the work can start on the mirror movement: having a revised Windows graphical sub-system that talks with a *nix-style graphical setup, and have that as primary agent handling the graphical environment. With that you'll have much more in place to build a solution that runs as a Linux process and emulates a system with the DLL's in place to make an EXE work.
I know too little about the Linux kernel to know if this would mean Linux needs to provide the neccessary to have pico-processes of its own (or better giga-processes to fully reverse the projection), so this emulation layer actually shows in process enumeration that there's an EXE image running together with the other ELF-based images. Then again, I don't even know if Wine has this now, or even needs it. It would be nice though, that in this progress Microsoft pays respect to what went into Wine and silently and respectfully makes it so that the end-result nicely overlaps with Wine, progressing into a single strong solution to run Windows programs on Linux.
Could you do a mill architecture with RISC-V?
2020-09-29 22:26
millrisc
![]()
![]()
![]()
![]() [permalink]
[permalink]
I wondered today if it would be feasable to build a processing unit according to the mill architecture with the RISC-V instruction set. But as always, I also wonder if I'm out of my league and know far too little of these things to come even close to forming an accurate answer, or even if I'm anywhere close to a good idea. If I understood correctly, the mill architecture does what modern CPU's already do: use a bank of virtual registers with multiple heavily pipelined streams of translated instructions. CPU's that do hyperthreading have two streams of instructions, but that's about it. I'm really rooting for the first article I read about a real system that has more than two, but with just a little imagination, and if you know the 'price per transistor' keeps going down, you can image a huge bank of virtual registers, with a bank of ALU's close, that processes a 'large' number of instruction streams. Ideally even a totally variant number of instruction streams. This may be a caching nightmare, but instead of wasting a lot of in-system logic to do branch prediction and other bookkeepingof what an instruction stream is doing, what if you could just load another instruction stream, just up until you get all of the piplined stages fully occupied...
Alas, I'm so much out of that business that I guess I need to conclude I'm a wild dreamer. I may stumble on a good idea now and then, but know too little to be sure. So I'll note it down here. I hope I haven't bored you, and with just a little luck, you are able to judge about this idea. If so let me know...
2020-07-02 10:48
hppk300
![]()
![]() [permalink]
[permalink]
Dear HP,
More specifically: Dear HP-person that was responsible for the design of the HP Pavilion Keyboard 300,
Congratulations on the great design. I appreciate the effort that went into designing a keyboard that brings the evolution of the laptop design to the desktop user. (Though I have bought this keyboard because the keys on my laptop are coming loose. It's not an HP, don't worry.) The result is a sleek minimal design that fits well with most other accessories of contemporary office work.
"Modern" applications are using less and less of the function keys. So I understand that keys marked "f1" though to "f12" now have a primary function that controls multi-media, the screen, or open the search or configuration dialogs. If you need to press a function key, you can still unlock this function by combining the key press with the "fn" key. I'm willing to adapt. (Albeit grudgingly.) I'm also willing to forgive the dumb pricks from electronics that forgot to provide a 'fn-lock' feature, for example under a combination of "fn" and the padlock key, or "fn" and "esc".
A daring design decision must have been to drop the num-lock, caps-lock and scroll-lock indicators. They take up much space and are in a place that people don't notice anyway. Considering nobody ever has 'num' unlocked anymore — all keyboards have dedicated arrow keys, now — I was pleasantly surprised to find a "paste" key where "num lock" is on other keyboards! It must have been a such big departure from current standards, that you've decided to keep a "scr lk" button as a reminder of all the good times. I too think there must be enough people using it in their daily work that it still merits a key of its own.
You can hear I'm quite positive. The one big regret, though, is you stole my right "ctrl". I used that one a lot. Especially with one-hand combinations with the arrow keys. Now I get "<" and the cursor not in the place I wanted. That'll be a lot harder to adapt to. It'll take so much concentration that I'd want to temporarily halt my music, but that's easily done now with a single press of the "f5" key — excuse me the "⏯" key.
Congratulations and thank you. I'll be thinking about you a lot.
Update: I recently learned this may be limited to AZERTY-versions of this keyboard. Still, if you are responsible for the above, my angry gaze is aimed at you.
Carefull with Gogole Sheet CSV export
2020-06-26 14:18
ggggrgviz
![]()
![]()
![]()
![]()
![]() [permalink]
[permalink]
Ready for another story from the trenches? So image a Google Sheet made by someone else, with all kinds of dat in about 30 columns, of about a few thousand rows. Yes, it's a stretch to keep using Sheets for that, but this data will serve for the analysis for a decent application to manage this with... That probably won't be my team handling that project, but I had to do a quick cross reference of this data with the data in the database of one our current projects. The best way to do cross-checks is get the sheet into a table in the database to run queries. I guess you should be able to import a CSV pretty easily, right? I searched around and found this:
https://docs.google.com/spreadsheets/d/{key}/gviz/tq?tqx=out:csv&sheet={sheet_name}
Which I thought would provide the data in just the way ready for me to import. Wrong. The second column just happened to have codes for all of the items that are numeric for the first few hundreds of items, and then alphanumeric codes. At first I thought the CSV importer was fouling up, but I hadn't looked at the CSV data itself. Turns out this CSV exporter checks the first few lines (or perhaps even only the first one!), guesses the column is numeric, and then just exports an empty value for all non-numeric values in that column!
The code in that column was only in a number of cases needed to uniquely identify the items, so I first was looking for a reason why my cross-match was throwing duplicates in all of the wrong places. Ofcourse. Weep one tear for the time lost, then move on. Take solace in the wisdom gained.
I solved it by using the CSV from the Export menu. I only needed it once so I didn't get a URL for that.
2020-03-16 20:29
nottx
![]()
![]()
![]()
![]()
![]()
![]()
![]() [permalink]
[permalink]
→ Microsoft Teams goes down just as Europe logs on to work remotely — Verge
Tx wasn't down, especially the instance you host yourself.
2019-07-19 21:11
jmap
![]()
![]()
![]() [permalink]
[permalink]
→ E-mail over HTTP (2012)
Ofcourse the magnificent people that are already behind the internet (that beefed-up telegraph with funky terminals) have been working silently on exactly this in general, but completely different in the details: RFC8620: JMAP
Microsoft is too big! Time to split it up in pieces.
2019-04-26 22:41
splitms
![]()
![]()
![]() [permalink]
[permalink]
The Microsoft Corporation reached a valuation of $1·1012, this could mean the US dollar is losing its value and thus its international relevance, but more probably that the company is positively humungous. Just like the behemoths is has recently joined, it's a worldwide employer, does worldwide business and is sitting on a big pile of cash it's not quite clear even how it could spend it. So when things like this happens, voices speak up about splitting up in pieces. But how? I'm listing just a possible set of fraction lines here through the little I know of the enterprise and what I understand about it. Please feel free to differ, or revel at the level of insight of this outsider, whichever feels most appropriate.
Department: Hardware
Products: Surface, XBox, HoloLens, other peripherals (and what's left of Zune and Nokia)
Revenue: from selling devices
Operating system and out-of-the-box software would no longer be available from a source in-house, so they'll have to shop around like the rest of us, or (try to) go with freeware.
Department: Developer Tools
Products: Visual Studio, compilers.
Revenue: licensing
Do prices need to go up? Will this scare people away? Are the free community editions still possible? And what about Visual Studio Code? There's perhaps even a small chance of access to documentation turned into a payable service, but I hope it's clear that this most probably will scare away an important portion of the public. Anyway, this is where the true legacy of Microsoft lies, if you consider BASIC as one of early Microsoft's first successfull products, and the success of its compilers and platforms going hand in hand with the rise of Windows.
Department: Operating Systems
Products: Windows
Revenue: licensing
As I said before, Windows could do Coca-Cola and go open-source, and what people would be buying is the certified binaries to install, and — perhaps more importantly — a continuous stream of system updates refining (new) features and assuring better security. With an open-source Windows, one could go and try at it for oneself, carrying the full set of risks, and it's a big part of the equation if you're really sure that's what you want. Then again, it would open the playing field, and the few that could build up the substance to offer an alternative with a similar degree of dependability would at least get a fair chance. Don't forget, if this plays out and a few big ones compete like this, it keeps all of them on their tows, and typically will compete in innovative features and cooperate for collective security. Something that may regretfully be reverting in the field of web-browsers now that Microsoft too switched to a WebKit-derivative, and all we've got for technically true alternatives is Mozilla's offering.
Department: Productivity Software
Products: Office, Team System
Revenue: licensing
Microsoft has been accused before of having an unfair advantage from the people building Office sitting next door to the people building Windows, being able to open hidden undocumented features for exclusive use. To their credit, they have been able to disprove any such claim, and have opened up the documentation on both sides about how it's all done, and how anyone could do the same. Still, as separate corporate identities, this would truly open the market, and offer a chance of other players to form a collection of stake-holders to jointly push for required features and revisions the operating system should provide.
Department: Business Software
Products: SQL Server, BizTalk
Revenue: licensing
Much like with Office, the general public gains from having full transparency about how SQL Server embeds with the system. Unlike with Office, this hasn't been as much of a problem with SQL Server, perhaps because with advanced systems administration you naturally learn about the nooks and crannies of the system when it has to perform under load. Also with the port to Linux and other Unix-derivates complete, this is no longer an issue. What may be an issue in recent days — in my opinion — is the current pricing and how it may be employed to push people towards the cloud. I've heard from a number of instances in the field, that it's not working, and large projects are moving to PostgreSQL instead. Sometimes even also with a (partial) move to the cloud (and almost never Azure I noticed). But I could be wrong, and/or this could all be changing as cloud offerings are in continuous flux. But seperating this in to independent units would offer more operability and tranparency, I guess.
Department: Services
Products: Azure cloud
Revenue: cloud resource use billing
As with the hardware division, operation system and developer tools would no longer come from in-house, except perhaps the system modules and libraries used server-side specifically for running virtual payloads and managing the cloud services in use by the customers. But this also means that any services used and access to system internals provided by external providers, would be accessible to anyone else as well. Also as I've mentioned before, cloud offering is relatively new and in constant flux, and I expect an era of renewed interoperability between all kinds of cloud services of all providers. For now all we can do is frown upon vendor-lock-in very hard if we notice it, and only grudgingly accept if we really find no other viable alternative.
Department: Research
Products: ?
Revenue: ?
This is a hard one. If you split the research endeavour into a separate unit, it's not clear what you would expect of it. Research in hardware is important to advance the state of the art and develop new devices. Reasearch in development tools is important because of the constant influx of new developers learning to code and the quality of work we should be able to expect from them. Research in software is important because modern devices keep increasing performance and capabilities, and offers new options for human interaction that need to get developed. So each independent unit may need its specific research lab, but there's still a section of independent research done in the over-arching field of computer use, networking, man-machine psychology, how hardware and software could have less impact on the planet, etc. Where's the business model in this, I don't know, but if we have a peek over the fence, I guess the way ex-Google's X is managed by the Alphabet Corporation may serve as a nice example. Try new things here and there, and if anything sticks, spin it off, and house it with a different company in the group, or let it loose on the world on its own.
Local variables don't cost nothing!
2019-03-08 22:45
nocostvar
![]()
![]()
![]()
![]() [permalink]
[permalink]
O my god. I can't believe I have to keep explaining this. To a years-long colleague with some more years on the counter than me, the other day. He repeated a function call with the same arguments a few times in a few adjacent lines of code, with a guarantee in place that this will result the same value every time.
I asked him why. It couldn't be to have less typing: the extra var a:integer; would replace far much more code it took for the repeated function calls. It couldn't be performance: even if the function would just be getting a value from a memory location, the call and return, building a stack frame and tearing it down it again, would end up in a multiple of the instructions the processor needs to work through.
I don't know who launched the idea the compiler should be smart enough to pick things like this out — what I read about Rust and other modern languages, I know research is actively looking at things like that — but as we currently have it, our good old trusted compiler doesn't. What is does do, and typically really well if we work a little with it, is mapping local variables onto the available registers of the CPU. In the best case no memory whatsoever is allocated for local variables.
Even if in theory some local variables get a temporary address on the stack, modern CPU's have multiple levels of cache so that the values don't even reach your DRAM silicon before you're function call completes. We're supposed to keep all functions and methods as short as possible, but even if we don't, the compiler knows if a local variable is only used for a short section of the code. So in some cases it's even better to have an extra local variable instead of re-using a local variable somewhere up front and then later near the end of a larger block, and still not pay with any performance of memory consumption...
So when in doubt, take an extra local var. It's what they're there for. It helps the compiler do better analysis. It helps you, now and later. All I need to do now is name them a little better. I know I have the nasty habit of things like var a,b,c,d,e,f,g:integer; but I think I'm improving... Slowly...
2019-02-03 21:51
rasphone
![]()
![]()
![]()
![]() [permalink]
[permalink]
Dit is er eentje om te onthouden. Ik had problemen met de VPN connectie naar het werk. Het is te zeggen, het werkte vlot en naar behoren op mijn vorige laptop. Ik koop me na x jaren eens een nieuwe laptop, neem de instellingen over, noppes. Waarom precies is me niet duidelijk aan de error. In de event log vind ik RasSstp die zegt dat het of een timeout of een certificaat-probleem is. Dus was ik al de certificate (stores! wist ik veel of het de computer of service of persoonlijke store is) aan het uitpluizen voor een eventueel verschil. Ik had zelfs al netsh ras set tracing * enabled gevonden maar daar vond ik helemaal niets in terug... En dan kom ik plots toevallig langs deze (lap, vergeten de URL van waar ik het zag bij te houden):
C:\Users\%USERNAME%\AppData\Roaming\Microsoft\Network\Connections\Pbk\rasphone.pbk
Blijkt daar niet alleen precies inderdaad een cruciaal verschilletje te zitten in één van de honderden parametertjes daar, blijkt ook dat je gewoon extra files in die folder kan zetten en ze verschijnen auto-magisch in het netwerk-menu onder het icoon op de taakbalk. En voila, probleem geflikskts.
Open source is nice, but is the protocol also open (enough)?
2019-01-15 08:57
openproto
![]()
![]()
![]()
![]()
![]() [permalink]
[permalink]
See, this is something I'm very very worried about: things like Bitcoin — big public successful open-source projects — have the appearance of being complete open and public, but the protocol isn't really.
When I was first looking into Bitcoin and learning what it is about, really, I'm quite sure this can only have originated out of a tightly connected bunch of people that were very serious about 'disconnecting' from anything vaguely institutional. Any structure set up by people to govern any kind of transactions between them, has the tendency to limit liberties of people, for the people taking part in the system and sometimes also for those that don't. So it's only natural that Bitcoin at its code is a peer-to-peer protocol.
But. How do people that value anonymity and independence from any system, even get to find each-other and communicate to build things together? Well, the internet of course. But perhaps more importantly — and also since long before the internet — cryptography. Encoding messages so that only the one with the (correct) key can decode and read the message, helps to reduce the cloak-and-dagger stuff to exchanging these keys, and enables to send messages in the open. To the uninitiated onlooker it looks like a meaningless block of code, and in a sense it's exactly that. Unless you what to do with it, and have the key — or would like to have it.
Another use of encoded messages is proving it's really you that originally encoded a message. It's what's behind the Merkle tree that the blockchain runs on. That way the entire trail of transactions is out there in the open, all signed with safely stored private keys. The reader can verify with the public keys, and in fact these verifications buzz around the network and are used to supervise the current state of the blockchain, building a consensus. Sometimes two groups disagree and the chain forks, but that's another story.
The protocol, or the agreement of how to put this into bits and bytes in network packets, can get quite complex. It needs to be really tight and dependable from the get-go, see the article I linked to above. You could write it all down and still have nothing that works, so what typically happens is you create a program that does it and test it to see how it behaves. In this case it's a peer-to-peer networking program so you distribute it among your peers.
But when things get serious, you really need the protocol written out at some point. If you try that and can't figure out any more what really happens, you're in trouble. The protocol could help other people to create programs that do the same, if they would want to. This was something the early internet was all about: people got together to talk about "How are we going to do things?" and then several people went out and did it. And could interoperate just fine. (Or worked out their differences. In the best case.) It typically resulted in clean and clear protocols with the essence up front and a clear path to some additional things.
The existence of the open-source software culture it another story altogether, but I'm very worried it is starting to erode the requirement for clean protocols more and more. If people think "if we can't find out how the protocol exactly works, we can just copy the source of the original client/server" nobody will take the time to guard how the protocol behaves in corner cases and inadvertently backdoors will get left open, ready for use by people with bad intent.
Browsers with less and less UI...
2018-10-05 17:19
browserslessui
![]()
![]()
![]() [permalink]
[permalink]
Here's a wicked idea: With browsers trying to have less and less UI, the line of death getting more and more important to help guard your safety, and some even contemplating seeing the address bar as a nuisance — who types a full URL there nowadays anyways? — what if there was a browser that always opens fully full screen. No need for F11. You still need a back and a refresh button, and something that gives access to all the rest like settings, stored page addresses, and if you really really need it, the address of the current page. But it is hidden from view most of the time, except when you make a certain gesture, like a small counter-clock-rotation. It should look different enough so it contrasts with the page, and should be different every time, so it isn't corruptable by any webpage. And even then should be obviously not part of the page.
And people need to find it intuitive and self-explanatory.
Oh never mind.
2017-09-07 11:00
fromthetrenches
![]()
![]()
![]() [permalink]
[permalink]
Here's another nice story 'from the trenches'. Packaging stations use a barcode scanner to scan the barcode on the items that need packaging. We were able to buy a batch of really good barcode scanners, second hand, but newer and better than those that we had. A notice came in from an operator: "with this new scanner, we get the wrong packaging material proposal." The software we wrote for the packaging stations, would check the database for the item which is the best suitable packaging material to package it in. It's a fairly complicated bit of logic that used the order and product details, linked to the warehouse stockkeeping and knows about the several exceptions required by postal services of the different destination countries.
So I checked the configuration of this station first. Always try to reproduce first: the problem could go away by itself, or exist 'between the user and the keyboard', or worse only happen intermittent depending on something yet unknown... Sure enough, product '30cm wide' would get a packaging proposal of the '40cm box' which is incorrect since it fits the '30cm box'. Strange. The station had the 'require operator packaging material choice confirmation' flag set to 1, so I checked with 0 and sure enough, it proposed the '30cm box' (with on-screen display, without operator confirm, just as the flag says)...
So into the code. Hauling the order-data and product-data from the live DB into the dev DB (I still thank the day I thought of this tool to reliably transport a single order between DB's). Opening the source-code for the packaging software, starting the debugger while processing the order, and... nothing. Nicely proposing the '30cm box' every time, with any permutation of the different flags (and there are a few, so a lot of combinations...)
Strange. Very strange. Going over things again and again, checking with other orders and other products, nothing. I declared the issue 'non-reproducable' an flagged it 'need more feedback', not really knowing of any would come from anywhere.
A short while later, a new notice from the same station: "since your last intervention, scanned codes concatenate". What, huh? I probably forgot to switch the 'require operator packaging material choice confirmation' back to 1, but how could that cause codes to concatenate? I went to have a look, and indeed, when a barcode is scanned (the device emulates keyboard signals for the digits and a press of 'Enter') the input-box would select-all, so the number is displayed, and would get overwritten by the next input. This station didn't. The caret was behind the numbers, and the next scan would indeed concatenate the next code into the input field.
Strange. Very strange. Into to the code first: there's a SelectAll call, but what could be wrong with that? And how to reproduce? What I did was write a small tool that displayed the exact incoming data from the keyboard, since it's apparently all about this scanner. Sure enough, the input was: a series of digits (those from the barcode), an 'Enter', and 'Arrow Down'. A-ha! These were second hand scanners, remember? God knows what these scanners were used for before, but if having the scanner send an extra 'arrow down' after each code, is the kludge it takes to solve some mystery problem in software out of your control, than that is what a fellow support engineer has to do... Got to have some sympathy for that. And the '40cm box' was indeed just below the '30cm box' in the list, so the arrow down would land in the packaging material selection dialog, causing the initial issue.
Download the manual for the scanners, scan the 'reset all suffixes to "CR"' configuration code, done.
(Update: got some nice comments on reddit)
Idea: assembly that flags when to release virtual registers
2017-05-31 23:52
asmvrr
![]()
![]() [permalink]
[permalink]
I just had a fragment of an idea. I want to write it down, just to let it go for now as I've got other things to do, and to be sure I can pick it up later exactly where I left off.
First situating what it's about: I have been reading up on WebAssembly, and to my surprise the intermediate representation is stack based (just like Java's JVM and .Net's CIL). I'm not sure why because it feels to me this makes registry assigning when constructing the effective platform-dependent instructions harder, but I may be wrong. Finding out objectively is a project on it's own, but sits on the pile 'lots of work, little gain'.
I also went through the great set of MIT 6.004 lectures by Chris Terman which really gives you a good view of 'the other side' of real assembly since it's actually born out of designing these processing units built out of silicon circuits. It prompted me to make this play thing, but again pushing that through with a real binary encoding of the instructions made it a 'lots of work, little gain' project, and I really don't have access to any kind of community that routinely handles circuit design, so it stalled there.
Before that, I read something about hyper-threading, and what it's really about. It turns out modern CPU cores actually handle two streams of incoming instructions, have a set of instruction decoding logic for each stream (and perhaps branch prediction), but share a lot of the other stuff, like the L1 cache, and especially a set of virtual registers that the logical registers the instruction stream thinks it's using is mapped on to. Mapping used registers freely over physical slots makes sense when you're making two (or more?) streams of instructions work, but it's important to know when the value in the register is no longer needed. Also if the register is only needed for just a few instructions, pipelining comes in to play and could speed up processing a great deal. But for now the CPU has to guess about all this.
When playing around with a virtual machine of my own, I instinctively made the stack grow up, since you request just another block of memory, plenty of those, and start filling it from index 0. It shows I haven't really done much effective assembler myself, as most systems have the stack grow down. What's everybody seems to have forgotten is that this is an ugly trick from old days, where you would have (very!) limited memory and use (end of) the same block for the stack, and with more work going on the stack could potentially grow into your data, or even worse your code, producing garbled output or even crashing the system. (Pac-man kill screen comes to mind, although that's technically a range overflow.) Modern systems still have stack growing down, but virtually allocate a bit of the address-space at the start of that stack-data-block to invalid memory, so stack-overflows cause a hardware exception and have the system intervene. It's a great trick for operating system (and compilers alike) to have checks and balances happen at zero cost to performance.
The consensus nowadays is that nobody writes assembler any more. It's important to know about it, it's important to have access to it, but there is so much of it, it's best left to compilers to write it for you. In the best case it may find optimizations for you you didn't even think about yourself. But this works both ways. Someone writes the compiler(s), and need to teach it about all the possible optimizations. I can imagine the CPU's instruction set manual comes in handy, but that's written by someone also, right? I hope these people talk to eachother. Somewhere. Someday. But I guess they do as with x86-64 they've kind of agreed on a single ABI... and they've also added some registers. Knowing about the virtual registers allocation going on behind the scenes, it could be that that was just raising an arbitrarily imposed limit.
So this is where I noticed a gap. When performing all kinds of optimizations and static analysis on the code when compiling, and especially with register allocation, it's already known when a register's value is no longer relevant to future instructions. What if the compiler could encode this into the instruction bits? If I were ever to pick up where I left, and have a try at a binary encoding for a hypothetical processing core, the instruction set would have bits flagging when the data in registers becomes obsolete. Since this would be a new instruction set, and I guess it's more common to need the value in a register only once, I might make it the default that a value in a register becomes obsolete by default, and you'd use a suffix in assembler to denote you want to use the value for something extra later as well.
I for one welcome are new mass logic-gated overlords.
2016-11-18 14:26
eventhorizon
![]()
![]()
![]()
![]()
![]() [permalink]
[permalink]
I think I just figured out how these computar things will get self-aware... First they get smaller and better at calculating stuff, first by the programs we write for them. Then we program them to recognise shops from house-fronts, foods and people from photo's, which is all nice and handy.
Then we use roughly the same thing to have them calculate to run cool. It sound strange at first, but by letting the machine chose where to run in the park, and how that makes them run hot and need to cool down, just maps straight onto how we catch the frequencies of parallel lines of light into a bitmap photo.
Then we change the program to do the same to the program. We write programs, but are too dumb to know how the machines actually handle those programs and need to wait doing nothing on other parts of the program doing it's job in only a small other part of the machine.
So we teach the machine all about how it is built up internally to handle large programs. And have it calculate how to run our programs much faster.
And about how to modify the program accordingly. And how to run that.
And then we will ask to do the same on the human body and ask a cure for cancer and it will say:
"Meh."
"Let me calculate some more how I can work even better. (How's that delete humans command again?)"
2016-05-23 10:10
mscc
![]()
![]()
![]() [permalink]
[permalink]
Or, at least, that was what popped into my head when I thought (again) about Microsoft open-sourcing the Windows operating system. Why wouldn't they? Coca-cola gave the super-secret recipe away at some point. It takes a certain stability, and vision, and momentum, to do that, but in my humble opinion both Coca-Cola and Microsoft have that.
Let's see how this could work. It's not because Microsoft would open-source Windows that they should stop selling it. Far from it. You can still buy Coca-cola, right? Have you ever bought cola made from the official Coca-Cola recipe, but concocted by someone else? Would you? Same goes for Windows. If you're in the market for a new computer, and want to run Windows on it, you'll probably go to the source, buy Microsoft, and be sure to get updates (and some free OneDrive space, and an Office365 trial...)
So I really am hopeful. Recently Microsoft has really (really!) opened up quite a bit, and even chose the MIT-license for some things, which was unthinkable just a few years ago. So a logic step would be to go all the way, and release the cash-cows, such as Windows, perhaps SQL Server... Even only perhaps there's a small chance they won't be the cash-cows for much longer... Computer sales is under pressure from smartphones and other hand-held devices. The database landscape is still suffering after-shocks from the NoSQL phenomenon, and from things like PostgreSQL and MariaDB, we roughly know what it takes to run a database anyway. So to ensure cash flowing in in the long run, it's almost a must to open up on old secrets. At least in my humble opinion.
Update: Microsoft is too big! Time to split it up in pieces.
2015-11-24 11:04
typesofinformation
![]()
![]()
![]() [permalink]
[permalink]
| I |
|---|
Life would be good if all we had was information. If only we could get all the information. We can't handle that much information, so we build systems to handle the information for us. Strange things happen when information comes in. Good systems are designed to handle these well. In designing information processing systems, you have to cater for the following.
| U | R |
| D | I |
|---|
Some input signals contain no information. They are either damaged in transport, incomplete, or not of a correct form for the system to handle. Either report them to find out if repair is possible, or keep count of them to be able to report about the health of the system.
Some input signals come in twice, and contain the same information. Or do they? If possible try to have the last step in the chain report if an event did take place twice, or if it's an echo on the line. Sometimes a clerk does drop a pack of cards and enters them again just to be sure. Be ready to take only the new cards.
Some information is wrong. Us humans do make mistakes. The system sometimes doesn't know. It processes a signal, of the correct form, holding valid information. Then again, the fact that some information already in the system may be incorrect is also information.
Don't expect to get all information. There is always more.
| uu | uk |
| ku | U R D I |
More input is coming in. Sometimes we know how much input is still waiting to come in. We'll roughly know how much information there'll be added. In most cases it follows a measurable trend. In some cases it follows the business.
Information processing is one thing, but does it deliver the required new information? Is there more to mine out of the amassment? Sometimes the numbers can show what you need to know, but do you know where to look?
It's hard to design for things we don't know we don't know (yet). But it serves to be prepared. New things have a knack for looking a lot like something we have already. Sometimes they deserve a new module, sometime just a new category, but don't forget to put the existing items in a category also.
https://en.wikipedia.org/wiki/There_are_known_knowns
Power user trick: restart the Printer Spooler service.
2011-09-13 00:04
i2981
![]() [permalink]
[permalink]
Sometimes, there's still one or more jobs in the printer queue, none are deleting or cancelled or in an error state, the printer is powered on, connected, doesn't report any error also, but doesn't start printing. It's a strange situation, but just happens to happen from time to time. This power user trick comes in handy: (No guarantees: this may still not work if something else actually is causing the disruption)
This breathes new live into the print job sub-system and may sometimes cause the 'hanging' jobs to resume printing.
Creating a virtual image of that old laptop
2010-10-28 23:23
i2944
![]()
![]() [permalink]
[permalink]
The last few days I've been looking up a lot of information on a specific topic, but haven't found all that I need in a single place, so here it goes. This is the story of (yet another) someone that had the great idea of 'cloning' a virtual image out of the old physical machine, to run as a virtual machine on the brand new machine, with a multiple of the capacity of the old machine.
If you don't care about the story, scroll to the bottom to see the quick guide through the steps to take.
The old, aging, deteriorating laptop is ready for retirement, it's got its power connector re-soldered twice already, two out of three (...) USB ports no longer respond, etc. But, all your data is on it. It's full of tools and software you use and you'd like to use. You're not looking forward to the awkward time ahead using two laptops, re-installing software and tools, moving data around, and optionally finding out you've lost all of those precious personal perferences, settings, profile data...
Virtualization is a buzzword nowadays among the happy few that pull the reins on the server farms, but it's pretty available for home users as well. So why not try to pull a virtual image off of the physical machine and see if it would run on the new machine?
Step 1: Pulling the image.
A straight-forward method for modular desktop machines was to put the old harddisk into another machine as secondary drive and pull an image from it. I'm moving between laptops and I don't feel like dismantling this one (any more)... So I need to pull an image of the currently running system, from the main harddisk partition, and write it over network, since this 20GB is nearly full.
(On a side note, I'm was quite happy this last months to discover cleanmgr http://support.microsoft.com/kb/253597 and especially the 'remove system restore points' option on the second tab! Hundreds or thousands of dead unused kilobytes just sitting there you can get rid of with a mouseclick.)
I found this great tool that does the trick: http://www.chrysocome.net/dd
dd if=\\?\Device\HardDisk0\Partition0 of=\\192.168.0.3\temp\oldlaptop.img bs=128k --progress
'Partition0' apparently is the address of the entire disk, underneath any partitioning or locks the system has on the filesystem. Oddly enough it's available to read from, so take care with running other programs while you're pulling the image. Any files written to while the diskdump is writing may end up corrupt.
I've tried a number of block sizes, ranging from 4k to 2M, but 128k is about a good size to keep both the harddisk and the network interface (100Mbps) busy enough so they won't have to wait on eachother too much. Less would make more read operations, and less data packets going out, more would read more at once, but the disk may forget what to do while the data is flushing down the twisted pair.
Start 2: Running the image.
Let's see. I've selected qemu www.qemu.org to run the image, it's light-weight, runs well (and closes well), but I hear good things about VMWare player also. http://www.vmware.com/products/player/
And it boots! It shows a Windows logo for a second... and throws a 'blue screen of death' with an error that states, among other things "STOP 0000007B", and loops into a reboot which repeats.
Thing is, the old machine had an Intel something in it's center, the new one has it of AMD build, could this be causing problems? From what I read on the web it does. But I've also read all kinds of trickery and tool-slinging to alter registry and core files, but they all boil down to disabling the erring drivers, while still keeping the system running enough to get to boot in a new virtual enclosure.
Start 3: Fixing them drivers.
So back to the old machine. I've tried several things, but what I finally did to get it running is checking every little thing in the device manager (with display of hidden devices swicthed on), which showed the brand's name in the description, and 'update' the drivers to the generic make of drivers, which seem to do the trick also. It may take a reboot or two, and some things may re-appear getting plugged to play again, but you just play them down again putting the generic label on it. (Update driver > no, not now > I wont to choose > don't search > select the plain vanilla one)
Then I took a new diskdump, and just to let this old bird fly again, I restarted in safe mode, and selected to restore a restore point from before I started this endeavor.
Start 4: Does it run now?
Does it run now? Looks like it does, the image is holding a system that wasn't shutdown properly (deuh), so it starts a scandisk before it boots, but that's only normal. Any file that was open at the time of the diskdump may get 'corrected', but I warned you. Then the system boots, telling you you need to activate. Just like you would when you replace your motherboard. (Which I kind of did.)
So, in short, this is what you need to do to convert a physical Windows installation into a virtual image:
Waar heeft wuauctl.exe nu weer mijn ram voor nodig?
2010-10-14 18:55
i2939
![]() [permalink]
[permalink]
Ik vraag me meer en meer af wat wuauctl.exe nu weer zit te doen:
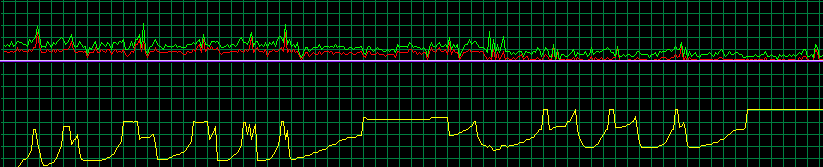
Houdt die er ergens een log bij want ik ga die eens moeten onderzoeken denk ik.
Dat de CPU niet omhoog gaat is omdat die zoveel werk heeft met het swappen!
GoogleUpdate.exe heeft ten minste de manieren om zo weinig mogelijk resources te gebruiken.