2017 ...
januari (4) februari (2) maart (6) april (3) mei (4) juni (2) juli augustus (1) september (3) oktober (5) november december (1)
2017-05-09 21:48
delphitrend
![]()
![]() [permalink]
[permalink]
Is there a language that has a single word for 'the feeling of being on a shrinking island'? Anyway, this is somewhat sad to see, especially that the few most recent Delphi versions gave the impression there was a new uptake with more people getting persuaded, but it doesn't show in the curve.
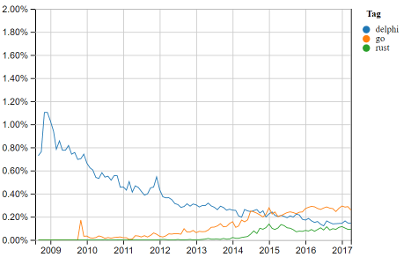
(via)
Checking xxm for PHP's vulnerabilities
2017-05-12 07:56
xxmphp1
![]()
![]()
![]() [permalink]
[permalink]
If I read about a newly discovered vulnerability related to PHP, for example this one here, I try to find out if it would apply to xxm as well.
In this case I guess there's nothing more than sending out the message, again and again, to sanitize your inputs, and poperly encode your output. Strings are never just strings. They are always an internal representation of a bit of textual data. So always think about that taking string values in, and preparing strings for output. A few weeks back I had to speak up to someone who wrote OutJSON:='{"field1":"'+value1+'"}';. Little Bobby Tables comes to mind, though I'm not sure 'JSON injection' could be so devastating as SQL injection. (And OutJSON:=JSON(['field1',value1]); is shorter!)
The other time I found out it's a really good idea to strip nastiness like EOL's (CRLF) from headers added to a response, just in case a malicious script is up to no good. Come to think of it, that's also just another case of properly sanitizing your inputs...
2017-05-19 20:09
murmur3
![]()
![]() [permalink]
[permalink]
@stijnsanders do you have MurMurHash3 code in pascal aswell ?
— _pusher_ (@_pusher_0x90) 12 mei 2017
i truly liked your optimized code for md5 and all those
Why, thank you. Eeuh, is it at all optimized? I took some decisions that may perform a little better than the reference implementation, but I haven't taken any time to compare to see if it actually performs any better or worse...
So MurMurHash3... Let's have a look, it's on wikipedia, so it's a thing. And the reference C implementation is in the public domain, great! Looks straight-forward enough, could boil down to a translation-job...
Rougly two hours later, got triple zero (0 errors, 0 warnings, 0 hints). Now for checking if I got it all right. Hmm, not much there, but those x32_64 match, so barring any typo's, assuming this pretty straight translate job will result in the expected behaviour for the other two functions, this should be it:
Idea: assembly that flags when to release virtual registers
2017-05-31 23:52
asmvrr
![]()
![]() [permalink]
[permalink]
I just had a fragment of an idea. I want to write it down, just to let it go for now as I've got other things to do, and to be sure I can pick it up later exactly where I left off.
First situating what it's about: I have been reading up on WebAssembly, and to my surprise the intermediate representation is stack based (just like Java's JVM and .Net's CIL). I'm not sure why because it feels to me this makes registry assigning when constructing the effective platform-dependent instructions harder, but I may be wrong. Finding out objectively is a project on it's own, but sits on the pile 'lots of work, little gain'.
I also went through the great set of MIT 6.004 lectures by Chris Terman which really gives you a good view of 'the other side' of real assembly since it's actually born out of designing these processing units built out of silicon circuits. It prompted me to make this play thing, but again pushing that through with a real binary encoding of the instructions made it a 'lots of work, little gain' project, and I really don't have access to any kind of community that routinely handles circuit design, so it stalled there.
Before that, I read something about hyper-threading, and what it's really about. It turns out modern CPU cores actually handle two streams of incoming instructions, have a set of instruction decoding logic for each stream (and perhaps branch prediction), but share a lot of the other stuff, like the L1 cache, and especially a set of virtual registers that the logical registers the instruction stream thinks it's using is mapped on to. Mapping used registers freely over physical slots makes sense when you're making two (or more?) streams of instructions work, but it's important to know when the value in the register is no longer needed. Also if the register is only needed for just a few instructions, pipelining comes in to play and could speed up processing a great deal. But for now the CPU has to guess about all this.
When playing around with a virtual machine of my own, I instinctively made the stack grow up, since you request just another block of memory, plenty of those, and start filling it from index 0. It shows I haven't really done much effective assembler myself, as most systems have the stack grow down. What's everybody seems to have forgotten is that this is an ugly trick from old days, where you would have (very!) limited memory and use (end of) the same block for the stack, and with more work going on the stack could potentially grow into your data, or even worse your code, producing garbled output or even crashing the system. (Pac-man kill screen comes to mind, although that's technically a range overflow.) Modern systems still have stack growing down, but virtually allocate a bit of the address-space at the start of that stack-data-block to invalid memory, so stack-overflows cause a hardware exception and have the system intervene. It's a great trick for operating system (and compilers alike) to have checks and balances happen at zero cost to performance.
The consensus nowadays is that nobody writes assembler any more. It's important to know about it, it's important to have access to it, but there is so much of it, it's best left to compilers to write it for you. In the best case it may find optimizations for you you didn't even think about yourself. But this works both ways. Someone writes the compiler(s), and need to teach it about all the possible optimizations. I can imagine the CPU's instruction set manual comes in handy, but that's written by someone also, right? I hope these people talk to eachother. Somewhere. Someday. But I guess they do as with x86-64 they've kind of agreed on a single ABI... and they've also added some registers. Knowing about the virtual registers allocation going on behind the scenes, it could be that that was just raising an arbitrarily imposed limit.
So this is where I noticed a gap. When performing all kinds of optimizations and static analysis on the code when compiling, and especially with register allocation, it's already known when a register's value is no longer relevant to future instructions. What if the compiler could encode this into the instruction bits? If I were ever to pick up where I left, and have a try at a binary encoding for a hypothetical processing core, the instruction set would have bits flagging when the data in registers becomes obsolete. Since this would be a new instruction set, and I guess it's more common to need the value in a register only once, I might make it the default that a value in a register becomes obsolete by default, and you'd use a suffix in assembler to denote you want to use the value for something extra later as well.